
Data Science
Data Science Technologies
Data science is a multidisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It combines aspects of mathematics, statistics, computer science, domain knowledge, and data visualization to uncover patterns, trends, and relationships that can be used to make data-driven decisions.
Here’s a comprehensive explanation covering various aspects of data science:
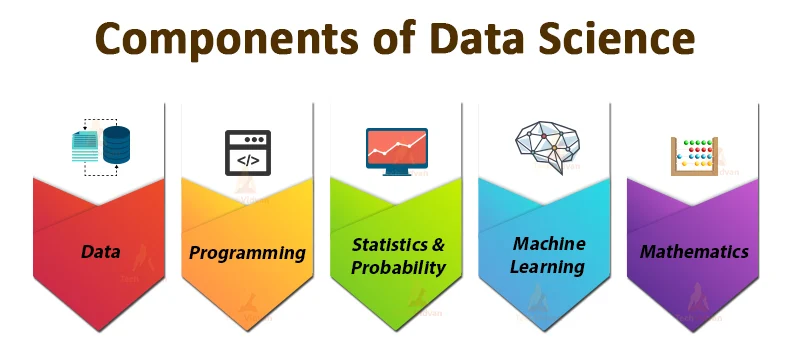
Key Components of Data Science
1. Data Collection and Storage
- Data Sources: Gathering data from various sources including databases, APIs, IoT devices, sensors, social media, and more.
- Data Acquisition: Extracting, ingesting, and storing data in structured or unstructured formats using databases, data lakes, or cloud storage solutions.
2. Data Pre-Processing
- Data Cleaning: Handling missing values, removing duplicates, and correcting errors to ensure data quality.
- Data Integration: Combining data from multiple sources into a unified dataset for analysis.
- Feature Engineering: Transforming raw data into meaningful features that enhance predictive model performance.
3. Exploratory Data Analysis (EDA)
- Descriptive Statistics: Summarizing data using measures such as mean, median, variance, and correlation.
- Data Visualization: Using charts, graphs, and plots to explore data distributions, relationships, and patterns.
- Hypothesis Testing: Using statistical tests to validate assumptions and draw conclusions from data.
4. Machine Learning & Stats Modelling
- Supervised Learning: Training models on labeled data to make predictions or classify new data.
- Unsupervised Learning: Identifying patterns and structures in unlabeled data (e.g., clustering, dimensionality reduction).
- Deep Learning: Neural network models for complex pattern recognition tasks, such as image recognition and natural language processing.
5. Evaluation and Validation
- Model Evaluation: Assessing model performance using metrics like accuracy, precision, recall, F1-score, and ROC curves.
- Cross-Validation: Splitting data into multiple subsets for training and testing to ensure model generalization.
- Bias-Variance Trade off: Balancing under fitting and over fitting to optimize model performance on new, unseen data.
6. Deployment and Monitoring
- Model Deployment: Integrating models into production systems for real-time predictions and decision-making.
- Model Monitoring: Continuously evaluating model performance and updating models as new data becomes available.
Data Science Technology Development
Wide-Ranging Applications
Data science finds applications across various industries and domains, including but not limited to:
- Finance: Risk assessment, fraud detection, algorithmic trading.
- Healthcare: Disease prediction, personalized medicine, medical image analysis.
- E-commerce: Customer segmentation, recommendation systems, market basket analysis.
- Marketing: Customer churn prediction, sentiment analysis, A/B testing.
- Manufacturing: Predictive maintenance, quality control, supply chain optimization.
- Telecommunications: Network optimization, customer service analytics, churn prediction.
- Government: Public policy analysis, crime prediction, urban planning.
Tools and Technologies & Challenges in Data Science
Tools and Technologies
- Programming Languages: Python, R, and SQL for data manipulation, analysis, and modeling.
- Libraries and Frameworks: Pandas, NumPy, Scikit-learn, TensorFlow, PyTorch for data processing, machine learning, and deep learning.
- Big Data Technologies: Hadoop, Spark, Kafka for handling large volumes of data and distributed computing.
- Visualization Tools: Matplotlib, Seaborn, Tableau for creating visual representations of data insights.
- Data Management: SQL databases (MySQL, PostgreSQL), NoSQL databases (MongoDB, Cassandra), and cloud-based data platforms (AWS, Google Cloud, Azure).
Challenges
- Data Quality: Ensuring data is accurate, complete, and reliable for analysis.
- Data Privacy: Handling sensitive information while complying with regulations (e.g., GDPR, HIPAA).
- Model Interpretability: Understanding and explaining how models make predictions.
- Scalability: Processing and analyzing large datasets efficiently.
- Continuous Learning: Keeping up with evolving algorithms, techniques, and industry trends.

Future Directions
AI and Automation: Integrating AI and automation into data science workflows for enhanced decision-making and efficiency.
Ethics and Fairness: Addressing ethical considerations in data collection, model development, and deployment to mitigate biases.
Edge Computing: Performing data analysis and machine learning inference closer to the data source to reduce latency and improve real-time decision-making.
Interdisciplinary Collaboration: Fostering collaboration between data scientists, domain experts, and business stakeholders to solve complex challenges and drive innovation.
In conclusion, data science plays a crucial role in extracting actionable insights from data to drive business decisions, improve processes, and innovate across industries. Its interdisciplinary nature and continuous evolution make it a dynamic and impactful field in the era of big data and digital transformation.